Another review published at .
I have recently explored a course offered by Harvard School of Engineering and Applied Science – CS109 Data Science. It provides insightful examples of how Machine Learning (ML) and statistical analysis can be used in real life.
General overview
The learner can find a very detailed description of the course in the . Students are expected to have prior programming experience and also understand basics of statistics. The main focus of this course is to teach students to deal with data (collect and prepare it), make useful predictions and analyse the collected data.
A particularly nice feature of the course is the way it is organised compared to some other MOOC learning platforms – one can find lecture slides here. This option provides the learner with the opportunity to quickly skim through the material and decide what lectures to watch. It can be also used for future reference. All the video lectures of this course can be found here.
In general, I liked the course, although I did have some issues. However, I would not agree with the slightly negative review by Vincent Granville, who criticizes the course for not including information about processing of real time data, API building etc. I see this course as more introductory. Even though it focuses on practical aspects of working with data, I believe the lecturers did not set up a goal of preparing you to start a job in data science and big data analytics straight away. However, I would agree with Vincent that some parts of the course are statistics heavy. This aspect can be explained by the fact that one of the instructors, , comes from Statistics. Another instructor, Hanspeter Pfister, specializes more in visual computing. This course is certainly more statistics orientated than the previously described courses of and .
Some highlights of the course
I will try to highlight some lectures I have enjoyed the most.
I particularly liked the lectures about visualisation (Lecture 2 – ” Process, Data, and Visual Attributes” and Lecture 3 – ” Statisical Graphs”). Perhaps, my favourite figure from the whole course (appears in Lecture 3):
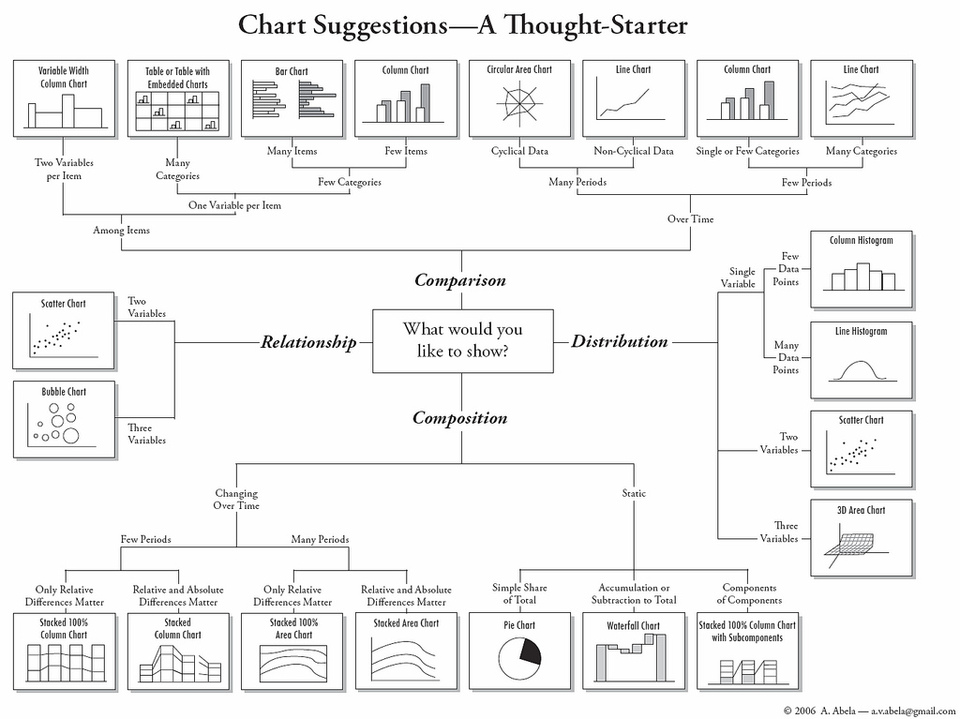
Chart suggestions – A Thought-Starter
Lecture 13 (“Basic machine learning”) covers all the methods that are presently most popular in practical ML. All the notions are easily explained and are perfect as a light introduction in order to just pick up some main concepts. It also covers some techniques that are not usually discussed in ML courses but are widely used by modern ML practitioners. Here I mean, for example, Ensemble Methods: bootstrap, bagging, boosting (AdaBoost). The lecture provides details about Random Forests and Cascade learning as well.
Lecture 14 (“MapReduce and MRJob”) provides a very accessible and easy to understand explanation of MapReduce, and provides a quick presentation of how it can be used in Python.
I also found Lecture 20 (“Visual Story Telling. Messaging. Effective Presentations.”) to be a very useful and fascinating part of the course. The ideas discussed in this lecture will help the learner make their presentations more meaningful and effective. It does not only apply to those people who do data analytics, but to everyone who has to deliver successful presentations.
Practical part
Many colleagues of mine have found Python sessions especially helpful. Labs are orientated on practice and focus on libraries, techniques that can be useful for undertaking a data processing experiment yourself. It focuses on the topics which go in line with the main lectures, therefore providing skills to implement the ideas discussed in the lectures into real life. So it covers everything from web scrapping to using Random Forests and SVMs. Unlike some other classes it includes all the steps of data collection, preparation, analysis and visualisation and not only focuses on ML libraries.
This course also includes very inspirational presentations of the final projects where students show how they use their newly acquired skills to extract valuable information from various datasets.
This time I was exploring the course at my own pace, therefore I had no chance to experience how well staff supports people taking this course online. Also I was not able to check out the forum. So if you have taken the course and were actively participating in it, feel free to share your knowledge in comments.
I would recommend this course to everyone who is looking for a course that covers a wide range of very ‘hot’ topics: collection and preparation of data, Machine learning (Regression, SVM, Trees, Bayesian approach, Clustering, Random forests, PCA etc.), analysis of networks and visualisation. It does not go deep into details of all the algorithms but provides a lot of practical knowledge to get started.